K8S - 모니터링 개념과 실습(Prometheus, Grafana)
쿠버네티스에서 모니터링이란?
모니터링의 변화
여러 노드에서 다수의 파드를 관리해야하기 때문에 전통적인 Server-App 구조에 비해 모니터링 대상이 유동적.(1:1 -> 1:N 구조로 변화)
Application 상태에 따라 파드가 수시로 삭제/생성 되기 때문에 파드를 유동적으로 감시할 수 있도록 Tag, Label 등을 활용하여 모니터링 필요.
모니터링 방식
Push-based 모니터링
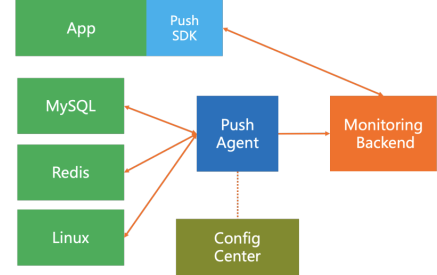
- 노드에서 모니터링 시스템에 정보 전달
- 모니터링 시스템이 전달되는 정보에 대한 조절 불가
- App은 Push SDK를 사용하여 모니터링 백엔드에 데이터 전송(SDK가 Push Agent 역할)
- SPOF 유발(노드와 파드가 급증하게 되면 모니터링 시스템에 부하 발생)
Pull-based 모니터링

- Discover System이 자동으로 타겟노드를 검색
- Pull Module에서는 공통 프로토콜을 사용하여 Remote End(그림에서 Apps, Mysql 등의 미들웨어나 시스템)에서 데이터를 가져옴
- 하지만 여러 미들웨어나 시스템에서 Pull 프로토콜이 호환되지 않기 때문에 Exporter라는 에이전트 필요(App에서는 풀링 기능을 사용하기 위해 Metrics Port로 수신 대기함)
- 메트릭 수집에 대한 권한을 모니터링 시스템이 소유
- SPOF 방지, 모니터링 대상에 대한 동적 대응
- Prometheus가 사용하는 방식
쿠버네티스의 모니터링 대상
클러스터
- api-server, kubelet, kube-controller-manager, kube-scheduler 등의 컴포넌트
파드
- 파드 상태(Healthy, UnHealthy)
- 파드 리소스 사용률(CPU, Memory, Disk)
노드
- 노드의 리소스 사용률(CPU, Memory, Disk)
모니터링의 지표
서비스를 운영하면서 모니터링에 필요한 데이터는 메트릭과 로그가 있음.
이 글에서는 메트릭 모니터링에 대해 다루기 때문에 ELK 스택은 제외하고 Prometheus, Grafana를 사용하여 실습함.
메트릭이란?
시스템의 성능과 상태에 대한 통계적인 정보(숫자)를 의미함. 예를 들어, CPU 사용률, 메모리 사용량, 응답 시간, 디스크 I/O 등이 있음.
메트릭을 분석하여 서비스의 성능을 추적하고, 용량 계획을 수립하며, 장애 시 경고 및 대응이 가능.
로그란?
시스템 및 애플리케이션 내부에서 발생하는 이벤트와 정보를 기록한 데이터. 로그는 디버깅, 오류 분석, 보안 검사 등 다양한 목적으로 사용됨.
로그를 분석하여 서비스의 작동 상태, 오류 발생 여부, 경고 및 알림 등을 추적하고 문제 식별 및 해결이 가능.
쿠버네티스 메트릭의 분류
쿠버네티스에서 수집하는 메트릭으로는 시스템 메트릭과 서비스 메트릭으로 나뉨.
시스템 메트릭이란?
노드나 쿠버네티스 시스템 컴포넌트의 CPU/Memory 사용량과 같은 시스템 관련 메트릭. 쿠버네티스 시스템 컴포넌트의 메트릭이냐 아니냐에 따라 코어 메트릭과 비 코어 메트릭으로 나뉨.
kubectl top 명령어에서 보여주는 값, HPA에서도 사용함.
서비스 메트릭이란?
클러스터내 생성된 애플리케이션 파드에 대한 메트릭. 애플리케이션의 응답속도, 500 에러 발생 건수 등 서비스 관련된 메트릭으로 HPA에서 커스텀 메트릭으로 사용할 수 있음.
모니터링 구분
쿠버네티스에서 모니터링은 Resource Metric Pipeline과 Full Metric Pipeline으로 구분 할 수 있음.
Resource Metric Pipeline

kubelet에 내장된 cAdvisor라는 모니터링 에이전트에서 노드와 파드의 현재 리소스 사용량을 수집하는 파이프라인.
이렇게 수집된 메트릭은 Metrics-server가 가져오고, API Server에 Metrics API를 제공하기 때문에 사용자가 kubectl top 명령어를 사용하여 확인 가능.
현재 리소스에 대한 값만 수집하고 따로 저장되지 않기 때문에 HPA, VPA 등의 Auto Scaling에 사용됨.
Full Metric Pipeline

Resource Metric을 포함하여 모니터링에 필요한 모든 메트릭을 수집하는 파이프라인.
Prometheus와 같은 별도의 에이전트를 통해 여러 메트릭을 수집할 수 있음.
쿠버네티스 모니터링 도구
쿠버네티스 프로젝트
- Metrics-server
kubelet으로부터 메트릭 수집.
Metrics-Server 애드온 설치 시 커스텀 API를 k8s Aggregator를 통해 API Server에 등록하기 때문에 kubectl top 명령어 사용 가능.
- kube-state-metrics
api-server로부터 쿠버네티스 전반적인 상태를 수집하여 보여줌(deploy/svc 개수, 재시작 횟수 등).
상용 모니터링
- Datadog, Newrelic, Dynatrace
비용 지불, 기술지원 가능.
오픈소스
- Prometheus
- Grafana
Prometheus
Prometheus란?
CNCF 오픈소스 모니터링 솔루션. 일정 시간마다 타겟으로부터 메트릭 수집, 수집된 메트릭을 가공할 수 있음.
조건에 따라 알람 발생.
Prometheus의 특징
- 다차원 데이터 모델
- PromQL 쿼리 랭귀지를 사용해 실시간 메트릭 수집
- 분산 스토리지 지원
- Pull based 모니터링
- Job 혹은 애플리케이션 파드의 이니셜 컨테이너와 같은 짧은 수명의 컨테이너 모니터링을 지원하는 Push Gateway
- 서비스 디스커버리를 통한 자동 타겟 설정
- 그래프 대시보드 지원
Prometheus 구조

메인 컴포넌트(Prometheus Server)
Prometheus의 메인 컴포넌트에는 Time Series DB(시계열 데이터베이스), Data Retrival, Http Server 가 있음.
TSDB - 메트릭 데이터를 발생한 시간별로 저장
Retrival - 쿠버네티스 클러스터의 모든 노드, 서비스, 애플리케이션의 메트릭을 수집하여 TSDB에 저장시킴
Http Server - 수집된 데이터를 Http Server를 통해 외부 접근이 가능하도록 함.(Prometheus web UI 혹은 Grafana 같은 시각화 대시보드에서 접근 가능)
Service Discovery
모니터링 타겟을 관리함. 어떤 타겟을 모니터링할지 파일로 정리한 file_sd가 있음.(이 글에서는 http_sd는 다루지 않음)
모니터링 타겟에 따라 서비스 디스커버리 포맷을 지원하고 있어 타겟에 맞춰 포맷을 지정
이러한 모니터링 타겟을 프로메테우스 오퍼레이터에서 ServiceMonitor라는 커스텀 리소스를 생성하여 관리
Short-lived jobs
생명주기가 짧은 Job의 경우 업무를 수행하고 종료되어 Pull 방식으로 메트릭을 수집할 수 없는 경우가 생기기 때문에 Pushgateway에 메트릭을 수집해두고 한 번에 가져옴
Exporter
모니터링 타겟에 대한 메트릭 생성
프로메테우스 Retrieval이 메트릭을 가져올 수 있도록 /metrics URL을 제공
Node-exporter, mysql-export 등 프로메테우스에 직접적으로 메트릭 URL을 제공하지 않는 미들웨어, 노드 등을 위해 개발
수집 메트릭의 설명
HELP : 메트릭 설명
TYPE : 메트릭 타입
- counter
- guage
- histogram, summary
Metric : 값
PromQL
프로메테우스 서버에 저장된 메트릭을 쿼리하기 위해 사용되는 쿼리 언어. 이러한 쿼리 언어를 적절히 조합하여 그라파나와 같은 시각화 대시보드에 커스텀하게 메트릭을 보여줄 수 있음.
Grafana
Grafana란?
메트릭, 로그, 추적 모니터링 및 분석 툴
데이터 시각화 및 쿼리, 알람 기능
다양한 데이터소스 지원(프로메테우스, InfluxDB, loki, mySQL, datadog, jira, cloudwatch 등)
Grafana의 특징
데이터 시각화 및 용도별 대시보드 사용
자유로운 그래프 배치
Text, Graph, Heatmap, Gauge, Chart, Candle Stick 등 다양한 방식으로 데이터 표현
실습
프로메테우스 설치 방법에는 여러가지가 있는데 이 글에서는 kube-prometheus로 프로메테우스, 그라파나를 동시에 설치함
kube-prometheus 설치(https://github.com/prometheus-operator/kube-prometheus)
# 아래 명령어로 kube-prometheus의 release-0.13 clone
$ git clone https://github.com/prometheus-operator/kube-prometheus.git -b release-0.13
# 폴더로 이동
$ cd kube-prometheus
# setup폴더에서 프로메테우스 오퍼레이터 사용에 필요한 CRD 설치 setup
$ kubectl create -f manifests/setup/
# 나머지 manifest도 설치
$ kubectl create -f manifests
# 파드 및 SVC 확인
$ kubectl get pod -n monitoring
$ kubectl get svc -n monitoring
prometheus, grafana, alertmanager 접속
대시보드에 접근하기 위해서는 해당 SVC를 Loadbalancer 형태(public cloud의 k8s 서비스면 가능)로 바꾸거나, kubectl port-forward 명령어로 접근해야됨.
이 글에서는 port-forward 명령어로 접근함.
# svc 명 확인
$ kubectl get svc -n monitoring
# 아래 명령어로 svc를 port-forward 해서 접근
$ kubectl --namespace monitoring port-forward svc/grafana 3000
브라우저로 grafana dashboard 접근
localhost:3000 번으로 접속 후 admin/admin 입력해서 로그인

대시보드 설정
유저들이 만든 대시보드를 사용하거나 K8S 환경(이 글에서는 AKS)에 맞는 대시보드 생성
출처
https://arisu1000.tistory.com/27855
https://www.alibabacloud.com/blog/pull-or-push-how-to-select-monitoring-systems_599007
https://k8s.aluopy.cn/ko/docs/tasks/debug/debug-cluster/resource-metrics-pipeline/
https://github.com/kubernetes-sigs/metrics-server